
TL/DR
AI bots = automated programs for tasks like data collection & interaction.
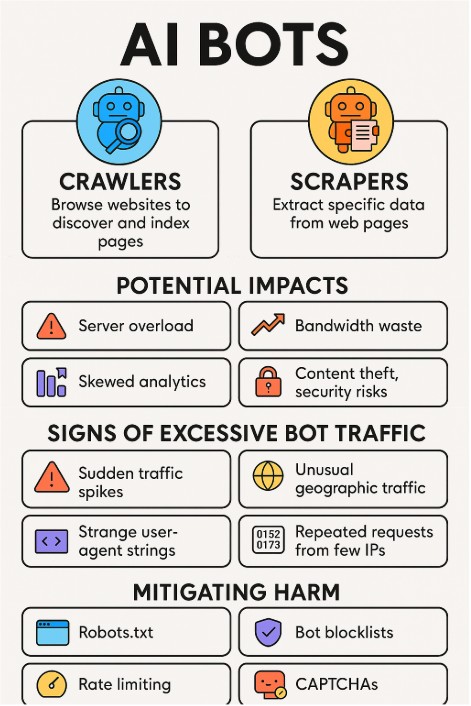
Crawlers = browse/index pages (e.g., Googlebot).
Scrapers = extract data (e.g., prices, reviews).
Good bots = search engines & social media crawlers.
Bad bots = cause server strain, bandwidth waste, skewed analytics, content theft, security risks.
Warning signs = sudden traffic spikes, high bounce rates, unusual geographic traffic, strange user agents, repeated requests from few IPs.
Defenses = robots.txt, rate limiting, bot blocklists, WAF/CDN rules, honeypots, CAPTCHAs.
Best practice = monitor server logs & analytics to detect/manage unwanted traffic.
What AI Bots Are
AI bots are automated software programs powered by artificial intelligence. They are designed to perform tasks that typically require human intelligence, such as understanding language, answering questions, analyzing data, or making recommendations.
These bots typically rely on machine learning and natural language processing (NLP) to interpret data and act intelligently rather than just following rigid, pre-coded rules. They come in many forms, but in this article, we are going to specifically discuss Crawler and Scraper Bots.
AI Crawler Bots
An AI crawler bot is an automated program that systematically browses websites, usually following links from one page to another, much like how a human would navigate the web. Crawlers are designed to discover and index content.
Purpose:
- Mainly used by search engines (Googlebot, Bingbot, etc.) to build search indexes.
- Helps identify new, updated, or deleted content on the web.
How it Works:
- Starts with a list of known URLs.
- Visits each page, scans text, images, and links.
- Follows the links to discover additional pages.
- Records the data structure (e.g., page title, keywords, metadata).
AI Aspect:
AI-enhanced crawlers may prioritize which pages to visit, assess content quality, and avoid irrelevant or duplicate pages more efficiently.
Think of these crawlers as web “explorers” that map out the internet for search and discovery.
AI Scraper Bots
An AI scraper bot goes a step further. Instead of just discovering pages, it extracts specific pieces of information from them.
Purpose:
- Gather structured data like product prices, reviews, financial data, job postings, or news headlines.
- Feed data into analytics tools, AI training datasets, or competitive monitoring systems.
How it Works:
- Accesses a webpage’s content (sometimes using the HTML structure, APIs, or even mimicking user interactions).
- Identifies and extracts the target data (e.g., all product names and prices).
- Stores the data in a database or spreadsheet for later use.
AI Aspect:
AI-powered scrapers can adapt to different website layouts, detect and filter out irrelevant content, and even use natural language processing (NLP) to interpret unstructured text.
Think of scrapers as web “collectors” that pull out exactly what they need from a page’s content.
Why These AI-Managed Bots Exist
Crawling is the process of systematically browsing the web to gather and index information. AI bots crawl websites for several reasons:
Search Engine Indexing
Search engines (like Google or Bing) use crawling bots to discover new and updated pages. This allows them to build searchable indexes so users can find relevant content quickly.
Training Data Collection
AI models often require large datasets. Crawlers can gather text, images, or structured data from websites to train machine learning models, improving their ability to understand language or make predictions.
Content Monitoring and Updates
Some bots crawl to track price changes, product availability, news updates, or other time-sensitive data. For example, e-commerce platforms and stock trackers rely heavily on crawlers.
SEO and Competitive Analysis
Companies use crawlers to analyze how their competitors present content, track backlinks, or check keyword usage for search engine optimization.
Compliance and Security
Crawlers check websites for broken links, vulnerabilities, or compliance with accessibility standards.
Why a Small Business Owner Should Care About These Types of Bots
Well, simply put, these crawlers and scrapers can actually do real harm to your website and quite easily affect your bottom line. Every day these bots can cause all sorts of issues you need to be aware of. These issues include:
High Server Loads & Even Outages
Aggressive crawlers can generate many concurrent requests, spiking CPU, memory, and I/O usage, causing slow pages or downtime.
Bandwidth Overuse / Cost Increases for You
Large-scale scraping (images, downloads, full-page fetches) can blow through bandwidth quotas and raise your hosting bills. Yea! Bet you didn’t think about that. These bots can literally cost you money.
Skewed Analytics and Bad Metrics
Bot traffic inflates visits, bounce rate, session duration, conversions, and makes it hard to measure real user behavior.
Index Bloat and SEO Issues
Scrapers that create thin/duplicate pages or cause many near-duplicates can dilute search rankings. Unwanted indexing of parameterized URLs or staging content harms SEO.
Content Theft & Copyright Loss
One of the most pressing concerns outlined is that AI crawlers scrape content without driving users back to the source site. Full-content scrapers republish your pages elsewhere. These are scraped copies of your pages, outranking originals or plagiarized content. This undermines business models built on ads, subscriptions, or gated access, since users may consume AI-generated summaries instead of visiting the original site. Over time, this reduces traffic, weakens brand visibility, and erodes content ownership. For publishers, this represents a direct threat: valuable intellectual property is effectively repackaged and redistributed by AI systems without credit or compensation.
Competitive Data Leakage
Price/product scrapers give competitors real-time pricing and inventory data that can undermine your strategy.
Security & Abuse
Some bots probe for vulnerabilities, harvest emails, try credential stuffing, or post spam on forms. That raises legal and security exposure. Bots can unintentionally or maliciously access sensitive content, including draft materials, “staging” environments, or embargoed announcements. This could result in premature leaks of financial results or other regulatory missteps. In addition, bots are sometimes used in credential stuffing attacks, spam form submissions, or vulnerability probing, turning what might seem like harmless crawling into serious security threats.
Evasion of Traditional Defenses Specifically with AI Bots
Unlike older bots that could be blocked by simple rules or CAPTCHAs, AI-driven crawlers are becoming much harder to detect. They can mimic human browsing behavior, rotate IPs, spoof user agents, and adapt their patterns in real-time. With AI’s ability to recognize defensive measures, bots can even learn to bypass basic protections. This makes them more resilient and more dangerous, since traditional defenses like IP blocking, rate limiting, or static rules are no longer enough to reliably stop them.
Log and Storage Bloat
Excess requests inflate log files, backups, and monitoring data volumes — increasing storage costs and slowing analysis.
User Experience Degradation
When your origin is busy serving bots, real users see slow load times, errors, or failed transactions.
Who Are The Organizations Behind These Bots?
Major Search Engine Crawlers (Legitimate)
These are the bots you usually want to allow, since they index your site for search engines.
- Googlebot – Google’s primary web crawler.
- Googlebot-Image / Googlebot-Video / Googlebot-News – Specialized Google crawlers.
- Bingbot – Microsoft’s search crawler.
- Slurp Bot – Yahoo’s crawler.
- DuckDuckBot – DuckDuckGo’s crawler.
Legitimate Bots – but not necessary to help your website unless you have business relationships in those countries.
- Baidu Spider – Baidu’s (China’s main search engine) crawler.
- Yandex Bot – Yandex’s (Russia’s main search engine) crawler.
- Sogou Spider – Chinese search engine bot.
- Naver Bot – Korean search engine bot.
- Seznam Bot – Czech search engine bot.
Social Media & Platform Crawlers
These bots crawl when someone shares a link, to generate previews.
- Facebook Crawler (Facebot)
- Twitterbot
- LinkedIn Bot
- Slackbot
- Telegram Bot
- Discord Bot
SEO & Marketing Crawlers
Tools that companies like us may use for audits, link tracking, and analytics.
- AhrefsBot
- SemrushBot
- Moz (rogerbot, dotbot)
- Majestic-12 Bot
- Screaming Frog SEO Spider (can show up if clients run audits).
Commercial Scraper Bots
These are often used for scraping product listings, prices, or competitor data. Many of these may appear as generic “Python-requests” or disguised user agents, but some are known:
- Scrapy (popular Python scraping framework; shows up as “Scrapy” UA unless spoofed).
- Python-urllib / Python-requests (generic scraping libraries).
- HTTrack (offline site downloader).
- wget / curl (command-line tools for scraping or downloading).
- libwww-perl (older scraper bot agent).
- DataForSEO / SerpApi bots (SEO/data extraction services).
Bad/Abusive Bots (Often Blocked)
These often cause performance or security issues.
- MJ12bot (Majestic crawler; semi-legit but very aggressive).
- DotBot (can be aggressive when scanning large sites).
- BLEXBot (SEO crawler, heavy load).
- Spam bots / email harvesters (often disguised as browsers but with odd UAs).
- Content theft scrapers (rotate UAs, often using datacenter IPs like AWS/Hetzner).
Bots for Large Language Model (LLM) Training & Information Retrieval:
- GPTBot: (OpenAI): For training OpenAI’s models.
- ClaudeBot: (Anthropic): For training Anthropic’s models.
- ChatGPT-User: (OpenAI): Used for live data retrieval for ChatGPT.
- PerplexityBot: (Perplexity AI): Used for gathering data for the Perplexity AI platform.
- Amazonbot: (Amazon): For Amazon’s AI-related services.
- Bytespider: (ByteDance): For data collection by ByteDance’s AI services.
- Meta-ExternalAgent: (Meta): Used by Meta for data retrieval.
- PetalBot: (Huawei): For Huawei’s search and AI needs.
- AppleBot-Extended: (Apple): For Apple’s Siri and Spotlight.
Other Crawlers
- CCBot: (Common Crawl): A crawler that collects web data for various research projects, often used in the AI field.
- Baiduspider: (Baidu): The primary crawler for Baidu, China’s dominant search engine.
- Applebot: (Apple): Gathers content for Apple services, including those that use AI.
So as you can see, there are quite a lot of them. Whether they are good, bad, or indifferent, you should be aware of them so you can decide what you want them to do.
Rise in AI-Specific Crawler Traffic
Cloudflare reports that traffic from AI crawlers has surged dramatically. For example, GPTBot (OpenAI’s crawler) traffic increased by around 147% year-over-year from mid-2024 to mid-2025, while Meta’s “Meta-ExternalAgent” traffic rose by an astonishing 843% in the same period. This highlights how quickly AI companies are scaling up web data collection to train and improve their models. Unlike traditional web crawlers, which were primarily used by search engines, these new AI crawlers are designed specifically to feed generative AI systems, creating a new and much larger demand on websites.
Signs You May Have a Bot Problem on Your Website
Server Performance Issues
- Sudden spikes in server load (CPU/RAM usage jumps without a real user surge).
- Slow page load times or site timeouts (too many concurrent requests).
- Frequent 503 / 504 errors (server unavailable or gateway timeout).
- Unusual bandwidth usage — large amounts of data being transferred without a corresponding increase in human traffic.
Analytics Red Flags
Abnormal traffic patterns
Sudden traffic surges at odd hours (e.g., 3AM).
Consistent spikes not tied to marketing campaigns or search engine indexing.
High bounce rates with near-zero engagement
Many sessions lasting only 0–1 seconds.
Pages viewed but no scrolling, clicks, or conversions.
Geographic anomalies
Large amounts of traffic from unexpected countries where you have no audience.
Device/browser mismatches
Lots of “Unknown” browsers or outdated versions (e.g., IE6, random user agents).
High traffic labeled as “Direct” or with missing referral info.
Log File & Security Signs
High request frequency from a few IPs
One IP hitting hundreds or thousands of pages per minute.
Odd User-Agent strings
Requests from known bad bots like python-requests, Scrapy, curl, wget.
User-Agents that pretend to be Chrome/Googlebot but don’t match real IP ranges.
Crawling sensitive or restricted areas
Bots repeatedly hitting /wp-admin/, /login, /xmlrpc.php, or /private/.
Repetitive URL patterns
Sequential requests like ?id=1, ?id=2, ?id=3 (data scraping).
Business Impact Indicators – THE BIG ONE
Inflated ad costs (bot traffic clicking ads or skewing data).
Scraped content appearing on other websites (a sign of scrapers taking your content).
Sudden increase in failed login attempts (credential-stuffing bots).
Inventory or pricing data misuse (competitors scraping your product catalog).
How to Detect Problematic Bots
- Inspect server access logs for high-request IPs, abnormal request rates, or unusual user agents.
- Look for patterns: same IP or IP ranges, same URL patterns, repeated GET for listing pages, many requests for images/assets.
- Use analytics filters to separate non-browser user agents and high-frequency sessions.
- Reverse DNS and WHOIS lookups on suspicious IPs (to see cloud providers or data centers).
- Watch for sudden spikes in 404s, 429s, or 5xx errors.
To help you with this, I’m partial to Cloudflare. We have had great success with them for over 15 years. They actually have an integrated solution to manage much of this for you.
Practical Mitigations
Simple Things your Web developer can implement for you.
- robots.txt — request-friendly crawlers respect it; use Disallow and Crawl-delay for polite scraping. (Note: malicious bots ignore it.)
- Rate-limit at the webserver — block/slow down IPs that exceed a requests-per-second threshold.
- Return 429 (Too Many Requests) for abusive patterns.
- Block obvious bad user agents and anonymous agents (but don’t over-block legitimate bots like Googlebot; verify their IPs first).
- Use a CDN — offload cacheable traffic and use CDN bot controls (Cloudflare, Fastly, etc.).
- Temporary IP blocks for clearly abusive ranges.
Medium/long-term (more robust) Things:
- Bot management / WAF solutions — Cloudflare Bot Management, Akamai, Imperva, PerimeterX, etc., can classify and mitigate at scale.
- Behavioral fingerprinting & challenge flows — use JavaScript challenges, CAPTCHA, or progressive profiling for suspicious flows.
- Honeypot traps — hidden links/forms that real users don’t trigger; bots that do can be automatically blocked.
- Require API keys / auth for data endpoints — expose structured data only through authenticated APIs, not raw HTML.
- Canonical tags / noindex rules — reduce SEO harm from duplicate or scraped pages.
- Legal approach — DMCA takedowns or cease-and-desist for abusive copy sites; place clear terms of use disallowing scraping.
Config Examples
Below are a few examples your web developer could copy/paste from this article to implement on your site.
robots.txt (example)
User-agent: * Crawl-delay: 10 Disallow: /private/ Disallow: /wp-admin/
Nginx simple rate-limit example
# in http {} limit_req_zone $binary_remote_addr zone=one:10m rate=5r/s; # in server or location {} limit_req zone=one burst=10 nodelay;
This example allows ~5 requests/second per IP with a small burst. Tune to your traffic.
Recommendations & Actionable Checklist
- Audit logs now — find top 20 IPs/UA strings by request volume.
- Block or rate-limit abusive IPs for immediate relief.
- Enable CDN + basic bot protection (if not already).
- Expose sensitive data only via authenticated APIs.
- Add honeypots + CAPTCHAs on forms and rate-limited endpoints.
- Filter bot traffic out of analytics (create filters for known bot UAs/IP ranges).
- Plan for WAF / Bot Management if scraping is frequent or costly.
- Document and enforce legal terms and a DMCA/contact process for stolen content.
A FINAL WORD OF CAUTION
Be careful not to block Googlebot, Bingbot, DuckDuckBot, etc. (legit crawlers). IF YOU DO, YOUR WEBSITE WON’T BE FOUND. Also, many malicious scrapers spoof User-Agents (pretend to be Chrome or Googlebot). For those, you’ll need rate limiting, IP reputation filters, or bot management (Cloudflare Bot Management, Akamai, etc.). Use this as your first layer of defense, then add rate-limiting rules for extra protection.
Distinguishing Between Permitted vs. Blocked Bots
Blocking all bots outright could cut off beneficial ones, like Googlebot, which drives search visibility. Instead, Cloudflare suggests a “block by default” stance, but with controlled permissions for trusted bots that provide real value. Site owners could allow AI crawlers limited access — for example, granting permission to index help documentation but blocking proprietary research or monetized content. This selective gating ensures websites protect sensitive assets while still leveraging the benefits of certain types of bot-driven exposure.
For more information about how to protect yourself, and at the same time save your hard-earned dollars being wasted by unwanted traffic, give us a call.



